-
[Machine Learning] 모델 해석 - Feature Importance, Permutation Importance, PDP, SHAPData Science/Machine Learning & Deep Learning 2021. 3. 3. 23:34
모델을 만든 후 해석하는데 있어 모델에서 어떠한 특성이 중요하게 작용하였는지,
모델이 예측을 하는데 특성이 어떻게 영향을 미쳤는지를 알 수 있는 방법에 대해 알아보겠습니다.
- Feature Importance, Permutation Importance, PDP, SHAP
Feature Importance
Feature Importance는 모델에서 특성의 중요도를 알 수 있으며, 각 특성을 모든 트리에 대해 평균 불순도감소를 계산한 값입니다.
속도가 빠르다는 장점이 있지만, high-cardinality(많은 카테고리를 가진) 특성에 대해서는 주의해야 합니다.
많은 노드에 사용되어 중요도가 높게 나타날 수 있기 때문입니다.
# 특성 중요도 rf = model_rf.named_steps['randomforestclassifier'] importances = pd.Series(rf.feature_importances_, X_train.columns) # 특성 중요도 시각화 %matplotlib inline import matplotlib.pyplot as plt n = 10 # 상위 10개 특성만 시각화 plt.figure(figsize=(10,n/2)) plt.title(f'Top {n} features') importances.sort_values()[-n:].plot.barh();
feature importance 그래프를 그려보면 '지점'이 가장 중요한 특성으로 작용했으며, 그 다음으로 평균 풍속, 최대 풍속 순으로 중요한 변수임을 알 수 있습니다.
Permutation Importance
Permutation Importance는 관심 있는 특성에 노이즈를 주어 특성이 자신의 역할을 하지 못하게 된 상태로 예측했을 때,
모델의 평가지표가 얼마나 감소했는지 성능을 측정합니다.
노이즈를 주는 가장 간단한 방법은 특성 값들을 샘플 내에서 섞는 것(permutation)입니다.
import warnings warnings.simplefilter(action='ignore', category=FutureWarning) import eli5 from eli5.sklearn import PermutationImportance encoder = OrdinalEncoder() X_train_encoded = encoder.fit_transform(X_train) # permuter 정의 permuter = PermutationImportance( model_rf.named_steps['randomforestclassifier'], scoring='f1', n_iter=5, random_state=2 ) # 스코어를 다시 계산기 위한 fit permuter.fit(X_train_encoded, y_train); feature_names = X_train.columns.tolist() eli5.show_weights( permuter, top=None, # None일 때 모든 특성 보여줌, 숫자 지정하면 수만큼 보여줌 feature_names=feature_names # list 형식 )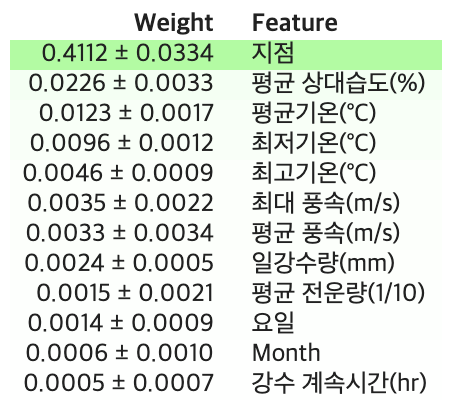
위와 같은 결과를 볼 수 있는데, 이를 통해 어떤 특성이 중요하게 작용했는지 알 수 있습니다.
Feature Importance에서와 마찬가지로 모델이 분류하는데 가장 중요한 역할을 한 특성은 지점입니다.
하지만 Feature Importance에서 지점 다음 중요한 특성이 평균 풍속, 최대 풍속 순이었던 반면,
Permutation Importance에서는 평균 상대습도, 평균 기온 순으로 나타나는 것을 확인할 수 있습니다.
Feature Importance와 Permutation Importance가 모델에서 특성의 중요도에 대한 정보만을 알려주었다면,
PDP와 SHAP는 특성의 값이 변함에 다라 타겟의 값이 어떻게 변하는지, 어떠한 영향을 주는지에 대해 알려줍니다.
PDP(Partial Dependence Plots)
PDP는 알아보고자 하는 특성이 타겟에 어떤 영향을 주는지, 특성과 타겟의 관계를 시각화를 통해 파악할 수 있습니다.
먼저 하나의 특성(평균 풍속)과 타겟의 관계를 알아보겠습니다.
# 1D PDP - '평균 풍속(m/s)' from pdpbox.pdp import pdp_isolate, pdp_plot feature = '평균 풍속(m/s)' isolated = pdp_isolate( model=model_xgb, dataset=X_train, model_features=X_train.columns, feature=feature ) plot_params = {'font_family': 'NanumBarunGothic'} # 한글 폰트 설정 pdp_plot(isolated, feature_name=feature, plot_params=plot_params);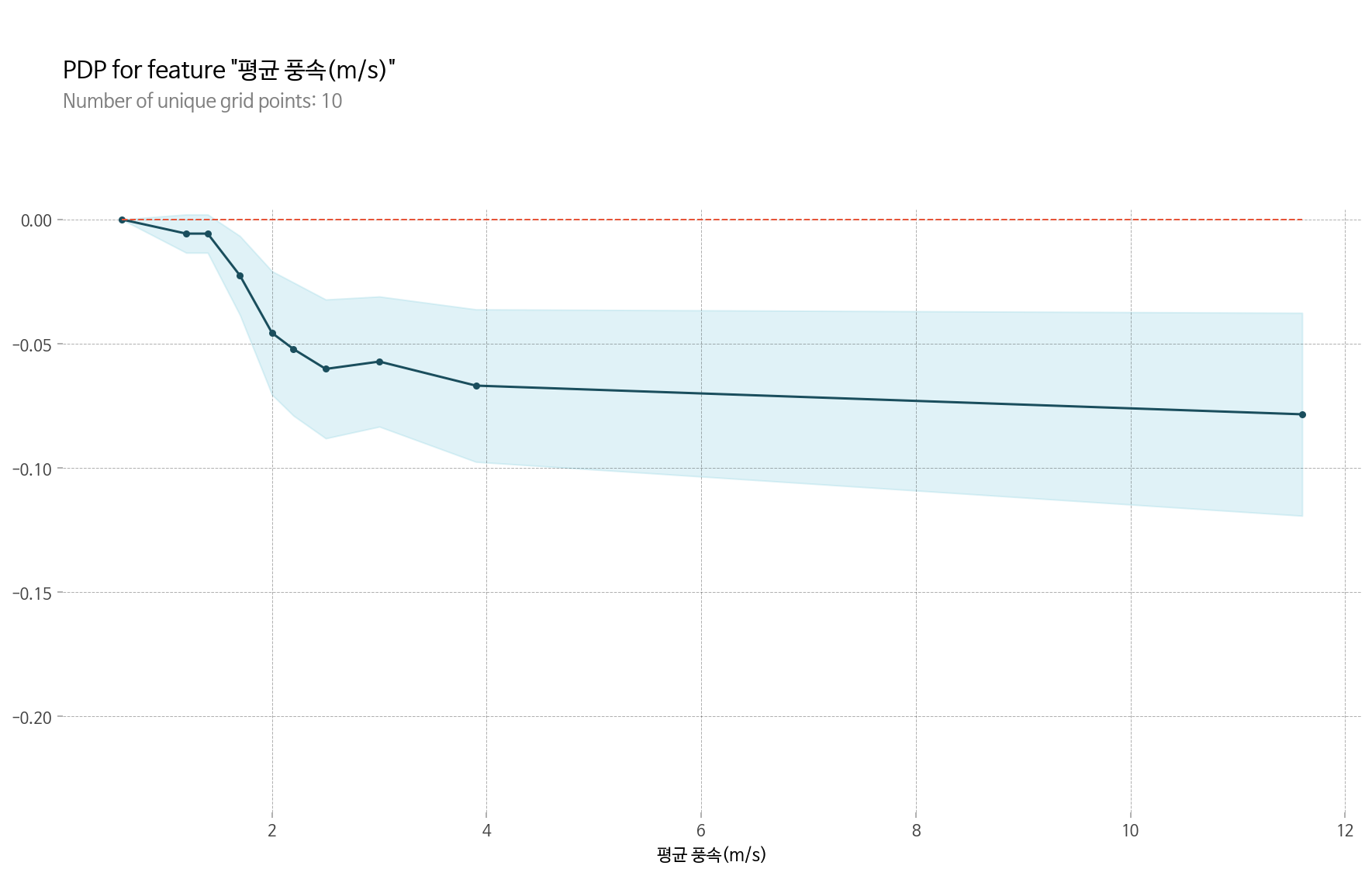
PDP를 통해서 평균 풍속이 증가하면 타겟 값에 부정적인 영향을 준다는 것을 알 수 있습니다.
특히 2 주위에서 크게 감소하며, 4 이후로는 감소가 크지 않은 것을 확인할 수 있습니다.
앞에서 하나의 특성(평균 풍속)과 타겟의 관계를 알아보았다면,
이제 두 특성(평균 풍속, 평균 기온)간에 어떠한 상호작용이 있는지 알아보겠습니다.
# 2D PDP - '평균 풍속(m/s)', '평균기온(°C)' from pdpbox.pdp import pdp_interact, pdp_interact_plot features = ['평균 풍속(m/s)', '평균기온(°C)'] interaction = pdp_interact( model=model_xgb, dataset=X_train, model_features=X_train.columns, features=features ) plot_params = {'font_family': 'NanumBarunGothic'} # 한글 폰트 적용 pdp_interact_plot(interaction, plot_type='grid', feature_names=features, plot_params=plot_params);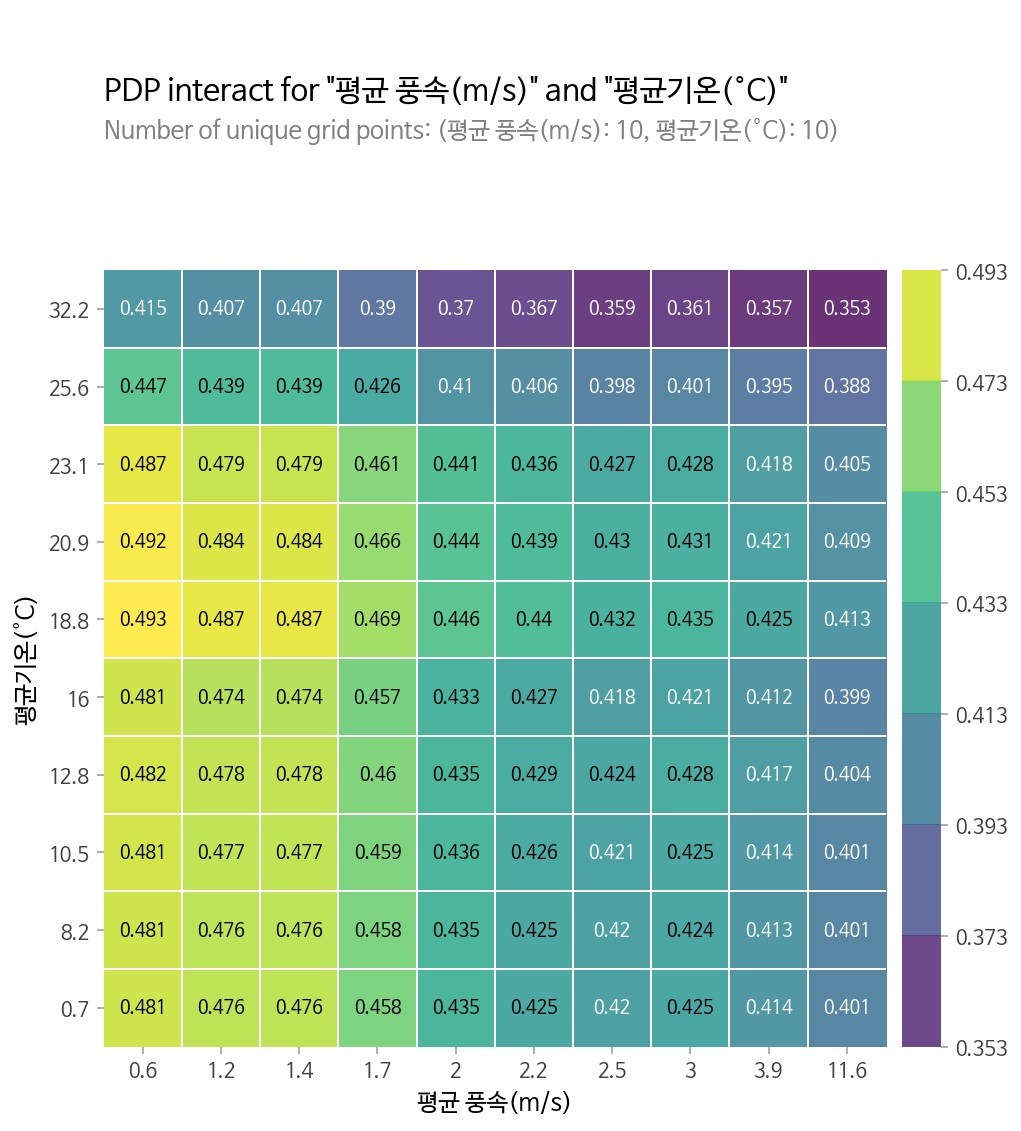
두 특성이 각각 x축과 y축에 표현이 되며, 타겟에 대한 영향은 색으로 나타나고 있습니다.
해당 모델은 이진 분류 모델이므로 평균 풍속이 낮고 평균기온이 낮거나 중간일 수록 타겟이 1으로 분류될 확률이 높아짐을 알 수 있습니다.
SHAP(SHapley Additive exPlanation)
SHAP은 게임이론에 나오는 shapley value를 통해 머신러닝에서 shapley value를 계산합니다.
특성들이 예측에 각자 기여한다고 할 때 shapley value를 머신이 예측하는데 특성이 얼마나 기여했는지에 측정하는데 활용합니다.
SHAP에서는 모델에서 하나의 관측치를 적용하여 특성들이 얼마나, 그리고 어떻게 기여하였는지를 알아볼 수 있습니다.
테스트 데이터에서 하나를 뽑아 적용해보겠습니다.
31번째 데이터로 실제 타겟값이 1이며, 모델의 예측도 1인 경우입니다.
# SHAP Force Plot import shap row = X_test_encoded.iloc[[30]] explainer = shap.TreeExplainer(model_xgb) shap_values = explainer.shap_values(row) shap.initjs() shap.force_plot( base_value=explainer.expected_value, shap_values=shap_values, features=row )
그래프를 보아 가장 크게 기여한 특성은 지점이며, 지점이 2 라는점이 1로 분류되는데 큰 기여를 했음을 알 수 있습니다.
그다음으로는 1월이라는 점, 평균 풍속이 0.9라는 점이 1로 분류되는데 큰 기여를 한 것으로 보입니다.
다음 그래프를 통해서는 어떤 특성이 예측을 하는데 많은 기여를 했는지를 알 수 있습니다.
shap_values = explainer.shap_values(X_test_encoded.iloc[:250]) shap.summary_plot(shap_values, X_train_encoded.iloc[:250], plot_type="bar")
모델이 예측을 하는데 있어 가장 큰 기여를 한 특성은 '지점'이며, 그 다음 큰 기여를 한 특성은 '요일'임을 알 수 있습니다.
SHAP plot을 통해서 각 특성이 어떤 범위에서 어떤 영향을 주었는지를 알아볼 수도 있습니다.
shap_values = explainer.shap_values(X_test_encoded.iloc[:250]) shap.summary_plot(shap_values, X_train_encoded.iloc[:250])
그래프 해석으로 특성마다 값에 따라서 타겟 값에 어떤 영향을 주고 있는지를 확인할 수 있는데
파란 점은 감소 또는 부정적인 영향을 주는 것이며, 붉은 점은 증가 또는 긍정적 영향을 주는 것으로 해석할 수 있습니다.
'Data Science > Machine Learning & Deep Learning' 카테고리의 다른 글
[Deep Learning] 역전파 ( Back Propagation ) (0) 2021.04.11 [Deep Learning] 인공신경망( Artificial Neural Networks )과 퍼셉트론( Perceptron ) (0) 2021.04.06 [Machine Learning] 교차검증 - Cross Validation, RandomizedSearchCV, GridSearchCV (0) 2021.02.21 [Machine Learning] RandomForest 랜덤 포레스트 & Threshold, ROC Curve, AUC (0) 2021.02.20 [Machine Learning] Logistic Regression 로지스틱회귀 (0) 2021.02.13