-
[Deep Learning] NLP - 텍스트 토큰화 ( Tokenization )Data Science/Machine Learning & Deep Learning 2021. 4. 13. 22:44
토큰(Token)은 보통 자연어 처리에서 최소단위로 사용되는데 단어, 형태소 등의 형태가 될 수 있습니다.
문서나 문장 등을 자연어 처리에 사용하기 위해 텍스트를 토큰으로 바꿔주는 토큰화(Tokenization)를 해야하는데,
토큰화를 올바르게 하기 위해서 아래와 같은 조건을 충족하는 것이 좋습니다.
- 반복 가능한 데이터 구조(list, generator 등)에 저장
- 가능하면 대문자 또는 소문자로 통일
- 가능하면 영문자, 숫자가 아닌 문자들을 제거해야함 - ex) 문장부호, 공백 등
NLP 라이브러리를 사용하기 앞서 파이썬을 이용하여 토큰화를 위한 함수를 만들어 보겠습니다.
import re # 정규식 # []: [] 사이 문자를 매치, ^: not regex = r"[^a-zA-Z0-9 ]" # 치환할 문자 subst = "" def tokenize(text): # 정규식 적용 tokens = re.sub(regex, subst, text) # 소문자로 치환 & split tokens = tokens.lower().split() return tokensSample Text를 이용하여 테스트를 해보겠습니다.
sample = "(Natural Language Processing) is easy!, DS!\n" tokenize(sample)
다음과 같이 잘 토큰화가 된 것을 볼 수 있습니다.
이제는 NLP 라이브러리인 Spacy를 이용한 토큰화를 해보겠습니다.
import spacy from spacy.tokenizer import Tokenizer # load the small english model nlp = spacy.load("en_core_web_sm") # Tokenizer 생성 tokenizer = Tokenizer(nlp.vocab)sample = "(Natural Language Processing) is easy!, DS!\n" [token.text for token in tokenizer(sample)]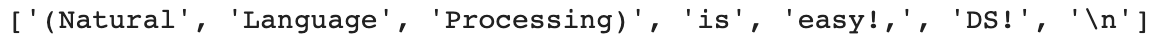
tokenizer.pipe 를 이용하여 토큰 스트림을 만들어 보겠습니다.
import spacy from spacy.tokenizer import Tokenizer # load the small english model nlp = spacy.load("en_core_web_sm") # Tokenizer 생성 tokenizer = Tokenizer(nlp.vocab) def tokenize(text): doc_token = [] for token in tokenizer(text): doc_token.append(token.text) return doc_tokensample = "(Natural Language Processing) is easy!, DS!\n" tokenize(sample)
위 두 예시를 통해서 단순히 Spacy를 이용해 토큰화를 진행하면 토큰화가 되긴 하지만 ,
대소문자가 섞여있고 문장기호, 공백 등이 포함되어 깔끔하지 못한 형태로 토큰화가 되는 것을 볼 수 있습니다.
spacy 문서를 살펴보면 token에 다음 속성들이 있음을 확인 할 수 있습니다.
- is_stop : Is the token part of a “stop list”?
- is_punct : Is the token punctuation?
- is_space : Does the token consist of whitespace characters?
불용어, 문장 부호, 공백을 해결하기 위해 위 속성들을 이용하여 토큰 스트림을 다시 만들어 보겠습니다.
import spacy from spacy.tokenizer import Tokenizer import re # load the small english model nlp = spacy.load("en_core_web_sm") # Tokenizer 생성 tokenizer = Tokenizer(nlp.vocab) def tokenize(text): regex = r"[^a-zA-Z0-9 ]" subst = "" tokens = re.sub(regex, subst, str(text)) doc_token = [] for token in tokenizer(tokens): if ((token.is_stop != True) & (token.is_punct != True) & (token.is_space != True)): doc_token.append(token.text.lower()) return doc_tokensample = "(Natural Language Processing) is easy!, DS!\n" tokenize(sample)
깔끔하게 원하는 형태로 토큰화가 되었습니다.
아래 링크에서 spacy token에 대해서 더 알아볼 수 있습니다.
Token · spaCy API Documentation
An individual token — i.e. a word, punctuation symbol, whitespace, etc.
spacy.io
'Data Science > Machine Learning & Deep Learning' 카테고리의 다른 글
[Deep Learning] NLP - 통계적 트리밍(Trimming) (0) 2021.04.15 [Deep Learning] NLP - 불용어 ( Stop Words ) 처리 (0) 2021.04.15 [Deep Learning] 손실함수(Loss Function) (0) 2021.04.13 [Deep Learning] 역전파 ( Back Propagation ) (0) 2021.04.11 [Deep Learning] 인공신경망( Artificial Neural Networks )과 퍼셉트론( Perceptron ) (0) 2021.04.06